Production-Quality Node.js Web Apps : Part II, Detecting Defects
This is the second part of a three part series on making node.js web apps that are (what I would consider to be) production quality. The first part really just covered the basics, so if you're missing some aspect covered in the basics, you're likely going to have some issues with the approaches discussed here.
First, I'm going to talk about a few major classes of defects and how to detect them.
I could go straight to talking about preventing/avoiding them, but detection is really the first step. You're simply not going to get a low-defect rate by just using prevention techniques without also using detection techniques. Try to avoid the junior engineer mindset of assuming that "being really careful" is enough to achieve a low defect rate. You can get a much lower defect rate and move much faster by putting systems in place where your running application is actively telling you about defects that it encounters. This really is a case where working smart pays much higher dividends than working hard.
The types of defects you're most likely to encounter
I'm a huge fan of constantly measuring the quality aspects that are measurable. You're not going to detect all possible bugs this way, but you will find a lot of them, and detection this way is a lot more comprehensive than manual testing and a lot faster than waiting for customers to complain.
There are (at least) 4 types of error scenarios that you're going to want to eliminate:
- restarts
- time-outs
- 500s
- logged errors
Restarts
Assuming you've got a service manager to restart your application when it fails and a cluster manager to restart a chlid process when one fails (like I talked about in Part I), one of the worst types of error-scenarios that you're likely to encounter will be when a child process dies and has to restart. It's a fairly common mistke to believe that once you have automatic restarting working, process failure is no longer a problem. That's really only the beginning of a solution to the problem though. Here's why:
-
Node.js is built to solve the C10K problem, so you should expect to have a high number of requests per process in progress at any given time.
-
The node process itself handles your web-serving, and there's no built-in request isolation like you might find in other frameworks like PHP, where one request can't have any direct effects on another request. With a node.js web application, any uncaught exception or unhandled
errorevent will bring down the entire server, including your thousands of connections in progress. -
Node.js's asynchronous nature and multiple ways to express errors (exceptions, error events, and callback parameters) make it difficult to anticipate or catch errors more holistically as your codebase gets larger, more complex, and has more external or 3rd-party dependencies.
These three factors combine to make restarts both deadly and difficult to avoid unless you're very careful.
Detection: The easiest way to detect these is to put metrics and logging at the earliest place in both your cluster child code and your cluster master code to tell you when the master or child processes start. If you want to remove the noise caused by new servers starting up, or normal deployments, then you may want to write something a little more complex that can specifically detect abnormal restarts (I've got a tiny utility for that called restart-o-meter too).
You might have an aggregated logging solution than can send you alerts based on substrings that it finds in the logs too, or that can feed directly into a time-series metrics system.
Time-outs
Time-outs are another type of failed request, where the server didn't respond within some threshold that you define. This is pretty common if you forget to call res.end(), or a response just takes too long.
Detection: You can just write a quick and dirty middleware like this to detect them:
app.use(function(req, res, next){
timeoutThreshold = 10000; // 10 seconds
res.timeoutCheck = setTimeout(function(){
metrics.increment("slowRequest");
console.error("slow request: ", req.method.toUpperCase(), req.url);
}, timeoutThreshold);
res.on('finish', function(evt){
clearTimeout(res.timeoutCheck);
});
next();
});(or you can grab this middleware I wrote that does basically the same thing).
500s
On a web application, one of the first things I want to ensure is that we're using proper status codes. This isn't just HTTP nerd talk (though no one will say I'm innocent of that), but rather a great system of easily categorizing the nature of your traffic going through your site. I've written about the common anti-patterns here, but the gist of it is:
Respond with 500-level errors if the problem was a bug in your app, and not in the client.
This lets you know that there was a problem, and it's your fault. Most likely you only ever need to know 500 Internal Server Error to accomplish this.
Respond with 400-level errors if the problem was a bug in the client.
This lets you know that there was a problem and it was the client app's fault. If you learn these 4 error codes, you'll have 90% of the cases covered:
- 400 Bad Request -- When it's a client error, and you don't have a better code than this, use this. You can always give more detail in the response body.
- 401 Not Authenticated -- When they need to be logged in, but aren't.
- 403 Forbidden -- When they're not allowed to do do something
- 404 Not Found -- When a url doesn't point to an existing thing.
If you don't use these status codes properly, you won't be able to distinguish between:
- successes and errors
- errors that are the server's responsibility and errors that are the client's responsibility.
These distinctions are dead-simple to make and massively important for determining if errors are occuring, and if so, where to start debugging.
If you're in the context of a request and you know to expect exceptions or error events from a specific piece of code, but don't know/care exactly what type of exception, you're probably going to want to log it with console.error() and respond with a 500, indicating to the user that there's a problem with your service. Here are a couple of common scenarios:
- the database is down, and this request needs it
- some unexpected error is caught
- some api for sending email couldn't connect to the smtp service
- etc, etc
These are all legitimate 500 scenarios that tell the user "hey the problem is on our end, and there's no problem with your request. You may be able to retry the exact same request later". A number of the "unexpected errors" that you might catch though will indicate that your user actually did send some sort of incorrect request. In that case, you want to respond with a reasonable 4xx error instead (often just a 400 for "Bad Request") that tells them what they did wrong.
Either way, you generally don't want 500s at all. I get rid of them by fixing the issues that caused them, or turning them into 4xxs where appropriate (eg. when bad user input is causing the 500), to tell the client that the problem is on their end. The only times that I don't try to change a response from a 500 is when it really is some kind of internal server error (like the database is down), and not some programming error on my part or a bad client request.
Detection: 500s are important enough that you're going to want to have a unified solution for them. There should be some simple function that you can call in all cases where you plan to respond with a 500 that will log your 500, the error that caused it, and the .stack property of that error, as well as incrementing a metric, like so:
var internalServerError = function(err, req, res, body){
console.log("500 ", req.method, req.url);
console.error("Internal Server Error", err, err.stack);
metrics.increment("internalServerError");
res.statusCode = 500;
res.end(body);
};Having a unified function you can call like this (possibly monkey-patched onto the response object by a middleware, for convenience) gives you the ability to change how 500's are logged and tracked everywhere, which is good, because you'll probably want to tweak it fairly often.
You're probably actually going to use this on most asynchronous functions in your HTTP handling code (controllers?) that you call that you don't expect an error on. Here's an example:
function(req, res){
db.user.findById(someId, function(err, user){
if (err) return internalServerError(err, req, res, "Internal Server Error");
// ...
// and normal stuff with the user object goes here
// ...
});
}In this case, I just expect to get a user back, and not get any errors (like the database is disconnected, or something), so I just put the 500 handler in the case that an err object is passed, and go back to my happy-path logic. If 500s start to show up there at runtime, I'll be able to decide if they should be converted to a 4xx error, or fixed.
For example if I start seeing errors where err.message is "User Not Found", as if the client requested a non-existant user, I might add 404 handling like so:
function(req, res){
db.user.findById(someId, function(err, user){
if (err) {
if (err.message === "User Not Found"){
res.status = 404;
return res.end("User not found!")
}
return internalServerError(err, req, res, "Internal Server Error");
}
// ...
// and normal stuff with the user object goes here
// ...
});
}Conversely, if I start seeing errors where err.message is "Database connection lost", which is a valid 500 scenario, I might not add any specific handling for that scenario. Instead, I'd start looking into solving how the database connection is getting lost.
If you're building a JSON API, I've got a great middleware for unified error-handling (and status codes in general) called json-status.
A unified error handler like this leaves you with the ability to expand all internal server error handling later too, when you get additional ideas. For example, We've also added the ability for it to log the requesting user's information, if the user is logged in.
Logged Errors
I often make liberal use of console.error() to log errors and their .stack properties when debugging restarts and 500s, or just reporting different errors that shouldn't necessarily have impact on the http response code (like errors in fire-and-forget function calls where we don't care about the result enough to call the request a failure).
Detection: I ended up adding a method to console called console.flog() (You can name the method whatever you want, instead of 'flog' of course! I'm just weird that way.) that acts just like console.error() (ultimately by calling it with the same arguments), but also increments a "logged error" metric like so:
console.flog = function(){
if (metrics.increment){
metrics.increment("loggedErrors");
// assume `metrics` is required earlier
}
var args = Array.prototype.slice.call(arguments);
if (process.env.NODE_ENV !== "testing"){
args.unshift("LOGGED ERROR:");
// put a prefix on error logs to make them easier to search for
}
console.error.apply(console, args);
};With this in place, you can convert all your console.error()s to console.flog()s and your metrics will be able to show you when logged errors are increasing.
It's nice to have it on console because it sort of makes sense there and console is available everywhere without being specifically require()ed. I'm normally against this kind of flagrant monkey-patching, but it's really just too convenient in this case.
Log Levels
I should note too that I don't use traditional log levels (error/debug/info/trace) anymore, because I don't find them all that useful. I'm logging everything as an error or not, and I generally just strive to keep the logs free of everything other than lines that indicate the requests being made like so:
...
POST /api/session 201
GET /api/status 200
POST /api/passwordReset 204
GET /api/admin.php 404
...
That doesn't mean that I don't sometimes need debug output, but it's so hard to know what debug output I need in advance that I just add it as needed and redeploy. I've just never found other log-levels to be useful.
More About Metrics
All of the efforts above have been to make defects self-reporting and visible. Like I said in the first part of this series, the greatest supplement to logging that I've found is the time-series metrics graph. Here's how it actually looks (on a live production system) in practice for the different types of defects that have been discussed here.
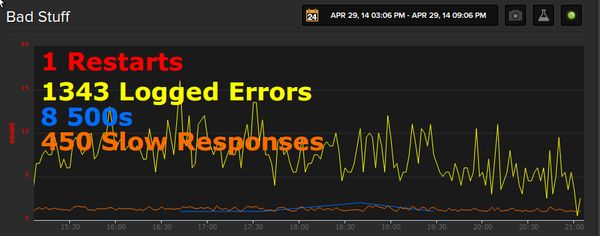
The way to make metrics most effective, is to keep them on a large video display in the room where everyone is working. It might seem like this shouldn't make a difference if everyone can just go to their own web browsers to see the dashboard whenever they want, but it absolutely has a huge difference in impact. Removing that minor impediment and just having metrics always available at a glance results in people checking them far more often.
Without metrics like this, and a reasonable aggregated logging solution, you are really flying blind, and won't have any idea what's going on in your system from one deployment to the next. I personally can't imagine going back to my old ways that didn't have these types of instrumentation.
← Back home