Vibe Reviewing
Steve Yegge shipped 225,000 lines of Go code he's never read. I just hit 170k lines on a side project without looking at the code. Vibe-coding is old news at this point, but what about vibe-reviewing? And possibly more terrifying: Can we build software without reading the code at all?
In the vibe-coding book, Yegge describes reviewing 10,000 lines of code a day. But he's not reading for elegance or comprehension. He's reviewing outcomes -- test results, whether the thing works. Code review becomes behavior review.
I'm exploring the same territory.
The Problem with Human Review
Sure, human code reviewers are slow and unreliable for stopping defects. The invention of pull-requests didn't bring in an unprecedented new age of software quality.
But the real problem with code review as a quality gate is that it comes at the end of the development process.
Code reviews as a quality gate are a massive source of waste where we discover problems way too late, requiring fixes that are more expensive than they need to be. My favourite W. Edwards Deming quote:
Let's make toast the American Way: I'll burn it, you scrape it.
If you've ever had a PR where someone says "I have an idea for a better approach entirely", you're scraping toast. Couldn't we instead just improve how we make things from the start and eliminate as much "scraping" as possible?
Even now in the age of AI, there are a million agents to automate PRs instead of employing agents to eliminate the need for review entirely. I've rarely heard anyone talk about using the same agents in precommit as they do for pull requests.
We've Done This Before
Remember when we had human QA gates before releases / deployment? Someone had to manually approve that the software worked before it could go out. Then we built automated tests and CI/CD pipelines and staged roll-outs and feature flags, and good observability and we managed to remove the humans from the loop. It was hard! We thought releases were so important that only humans could approve them. But then we figured out a better way.
The same pattern can happen with code review. We currently have human gates before code merges. But if we can automate the review -- really automate it, not just run some linter bot that everyone ignores -- we can remove humans from that loop too.
AI doesn't have to be perfect. It just has to be better than what we're doing today. (There's no question that it'll be faster. Waiting for a code review has got to be in the top 3 of software development soul-crushers.)
"But Review is for Knowledge Sharing!"
Common objection: code review spreads context across the team. Everyone learns the codebase by reviewing each other's code.
But most of that context is never used. You learn things in review that you never actually need. And deep codebase knowledge is devalued now anyway -- AI can navigate it for you.
Why learn preemptively when you can ask just-in-time? When you actually need to understand something, ask an agent. The context is there when you need it. You don't have to carry it around in your head.
Fresh Eyes Without Reading
I wrote myself a couple of useful Claude skills for review of the agent's work without looking at the agent's work.
The first is obviously /review . You can jam every opinion and quality check in there that you want. This is what you'll iterate on: every time you find an issue in a code review or a defect, consider adding the check to /review . Soon it will have a barrage of checks in it so extensive that no human can compete.
The second is /summary . All it does is summarize the code changes. It's useful for me to run on a clear context to see if the AI can figure out what the code is trying to do. And so it can find things that it's doing that are not coherent with the rest of the effort.
I use them both on a clear context ( /clear in claude code terminal ) so they have no hints about what to expect, and they have no biased agent (motivated to land the PR) interpreting the output. I don't read the code, I just point a fresh agent with these skills at it and see what comes back.
Lastly, things can still happen over time that make the code suck. Files get long, functions get long, "single sources of truth" show up in multiple places. I have a skill called /defrag that helps me find high-value refactorings. Basically everything that improves context management and quick semantic understanding.
- ensures short files/functions
- reduces hotspots (files that change all the time)
- consolidates sources of truth
- improves naming
- removes dead code
- adds missing tests.
The agents need refactoring just like we humans do if they're going to effectively and quickly navigate the codebase. This is the primary way I keep the agent successful as the codebase gets large. If it has to use up all its context figuring out your codebase, it will have no context left to intelligently handle your prompts.
I also ended up building a PR tool for myself for handling code review without reading code:
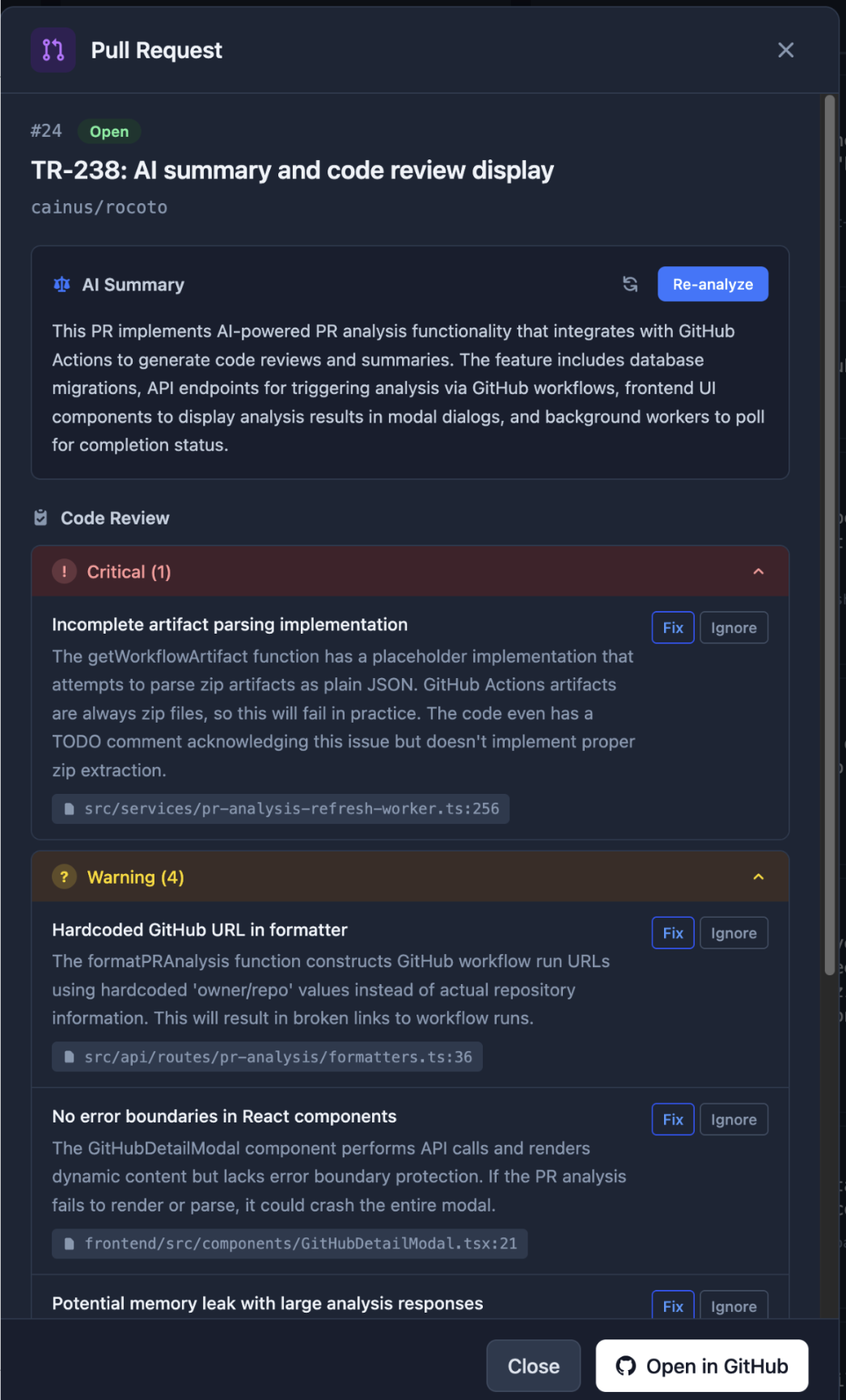
You still need to understand the code (at this point!) but you don't need to pore through it to figure out what needs to be fixed. AI can give you understanding at whatever resolution you need. Maybe you don't need to read all the code. I'm at 170K lines of code in this codebase without reading any code.
Reliable Systems from Unreliable Parts
You've probably seen some hallucinations, or just terrible results in your vibe-coding attempts. That doesn't mean all is lost though. Here's an analogy:
TCP is a reliable protocol built on top of an unreliable one. IP packets get lost, arrive out of order, get corrupted. But TCP uses redundancy, acknowledgments, and retries to create reliability from unreliability.
The same principle applies here. Individual AI agents are unreliable. They hallucinate. They make mistakes. They miss things. But multiple agents, possibly from different vendors and models, tasked with bringing different perspectives -- that's how you get to a more trustworthy solution.
There are consensus skills for Claude that do exactly this. Multiple agents review the same thing and have to reach agreement. If one agent hallucinates, the others catch it. Unreliable pieces used together to create reliable systems.
This is why I'm not worried about AI reliability for code review. We don't need each individual agent to be perfect. We just need the overall system to be reliable. And we know how to build reliable systems from unreliable parts. We've been doing it since TCP. I wrote more about this in Probabilistic to Deterministic.
Making It Work
A few practical things:
Reviews should happen precommit. Anything the review finds should be added to Claude -- CLAUDE.md files, custom slash commands, system prompts. If a review catches something once, your agent should ideally never make that mistake again. Put a feedback loop on your feedback loop.
Organize code for AI. Smaller files that fit in context windows. Clear naming that makes intent obvious without needing deep context. We used to organize code for humans. Now we organize it for AI too.
Lighten up your dev environment.
Well this is pretty wild: Now my IDE is code-free.
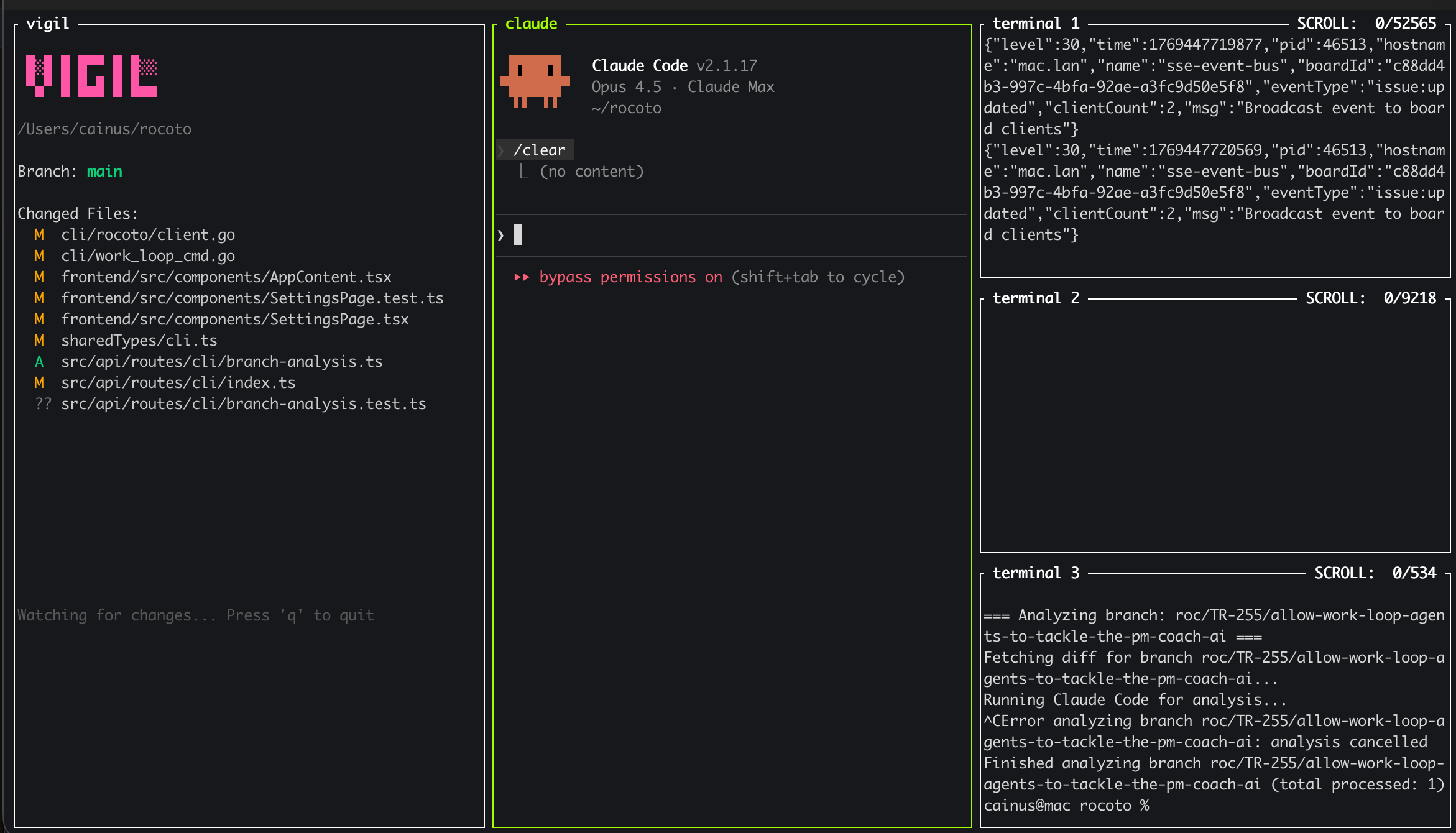
I use zellij to tile my windows, put claude code cli in the middle, with a few running terminals on the right. For git I love the auto-updating views that IDEs give you, so I vibe-coded a quick terminal app that just gives you that view. It took about three prompts to create and two of them were to suggest a good name. But there's nothing for viewing / editing code.
Conclusion
I don't at all think we're living in a post-code age (yet). But I think code reading and writing by humans might be over. To be clear: I definitely still need to know how to do software engineering to write anything complex beyond a one-shot, but of course coding is only part of software engineering, and it turns out it's a small part.
I have no idea what this means or what's next.
← Back home